Publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026
- ArXivTiny Aya: Bridging Scale and Multilingual DepthAlejandro R. Salamanca, Diana Abagyan, Daniel D’souza, Ammar Khairi, David Mora, Saurabh Dash, Viraat Aryabumi, Sara Rajaee, Mehrnaz Mofakhami, Ananya Sahu, Thomas Euyang, Brittawnya Prince, Madeline Smith, Hangyu Lin, Acyr Locatelli, Sara Hooker, Tom Kocmi, Aidan Gomez, Ivan Zhang, Phil Blunsom, Nick Frosst, Joelle Pineau, Beyza Ermis, Ahmet Üstün, Julia Kreutzer, and Marzieh Fadaee2026
@misc{salamanca2026tinyayabridgingscale, title = {Tiny Aya: Bridging Scale and Multilingual Depth}, author = {Salamanca, Alejandro R. and Abagyan, Diana and D'souza, Daniel and Khairi, Ammar and Mora, David and Dash, Saurabh and Aryabumi, Viraat and Rajaee, Sara and Mofakhami, Mehrnaz and Sahu, Ananya and Euyang, Thomas and Prince, Brittawnya and Smith, Madeline and Lin, Hangyu and Locatelli, Acyr and Hooker, Sara and Kocmi, Tom and Gomez, Aidan and Zhang, Ivan and Blunsom, Phil and Frosst, Nick and Pineau, Joelle and Ermis, Beyza and Üstün, Ahmet and Kreutzer, Julia and Fadaee, Marzieh}, year = {2026}, eprint = {2603.11510}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2603.11510}, } - ArXivCIRCLE: A Framework for Evaluating AI from a Real-World LensReva Schwartz, Carina Westling, Morgan Briggs, Marzieh Fadaee, Isar Nejadgholi, Matthew Holmes, Fariza Rashid, Maya Carlyle, Afaf Taïk, Kyra Wilson, Peter Douglas, Theodora Skeadas, Gabriella Waters, Rumman Chowdhury, and Thiago Lacerda2026
@misc{schwartz2026circleframeworkevaluatingai, title = {CIRCLE: A Framework for Evaluating AI from a Real-World Lens}, author = {Schwartz, Reva and Westling, Carina and Briggs, Morgan and Fadaee, Marzieh and Nejadgholi, Isar and Holmes, Matthew and Rashid, Fariza and Carlyle, Maya and Taïk, Afaf and Wilson, Kyra and Douglas, Peter and Skeadas, Theodora and Waters, Gabriella and Chowdhury, Rumman and Lacerda, Thiago}, year = {2026}, eprint = {2602.24055}, archiveprefix = {arXiv}, primaryclass = {cs.AI}, url = {https://arxiv.org/abs/2602.24055}, } - ArXivUnlocking Reasoning Capability on Machine Translation in Large Language ModelsSara Rajaee, Sebastian Vincent, Alexandre Berard, Marzieh Fadaee, Kelly Marchisio, and Tom Kocmi2026
@misc{rajaee2026unlockingreasoningcapabilitymachine, title = {Unlocking Reasoning Capability on Machine Translation in Large Language Models}, author = {Rajaee, Sara and Vincent, Sebastian and Berard, Alexandre and Fadaee, Marzieh and Marchisio, Kelly and Kocmi, Tom}, year = {2026}, eprint = {2602.14763}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2602.14763}, } - ArXivSimMerge: Learning to Select Merge Operators from Similarity SignalsOliver Bolton, Aakanksha, Arash Ahmadian, Sara Hooker, Marzieh Fadaee, and Beyza Ermis2026
@misc{bolton2026simmergelearningselectmerge, title = {SimMerge: Learning to Select Merge Operators from Similarity Signals}, author = {Bolton, Oliver and Aakanksha and Ahmadian, Arash and Hooker, Sara and Fadaee, Marzieh and Ermis, Beyza}, year = {2026}, eprint = {2601.09473}, archiveprefix = {arXiv}, primaryclass = {cs.LG}, url = {https://arxiv.org/abs/2601.09473}, }
2025
- WMTCommand-A-Translate: Raising the Bar of Machine Translation with Difficulty FilteringTom Kocmi, Arkady Arkhangorodsky, Alexandre Berard, Phil Blunsom, Samuel Cahyawijaya, Théo Dehaze, Marzieh Fadaee, Nicholas Frosst, Matthias Galle, Aidan Gomez, Nithya Govindarajan, Wei-Yin Ko, Julia Kreutzer, Kelly Marchisio, Ahmet Üstün, Sebastian Vincent, and Ivan ZhangIn Proceedings of the Tenth Conference on Machine Translation, Nov 2025
@inproceedings{kocmi-etal-2025-command, title = {Command-A-Translate: Raising the Bar of Machine Translation with Difficulty Filtering}, author = {Kocmi, Tom and Arkhangorodsky, Arkady and Berard, Alexandre and Blunsom, Phil and Cahyawijaya, Samuel and Dehaze, Th{\'e}o and Fadaee, Marzieh and Frosst, Nicholas and Galle, Matthias and Gomez, Aidan and Govindarajan, Nithya and Ko, Wei-Yin and Kreutzer, Julia and Marchisio, Kelly and {\"U}st{\"u}n, Ahmet and Vincent, Sebastian and Zhang, Ivan}, editor = {Haddow, Barry and Kocmi, Tom and Koehn, Philipp and Monz, Christof}, booktitle = {Proceedings of the Tenth Conference on Machine Translation}, month = nov, year = {2025}, address = {Suzhou, China}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2025.wmt-1.55/}, doi = {10.18653/v1/2025.wmt-1.55}, pages = {789--799}, isbn = {979-8-89176-341-8}, } - ArXivVerification Limits Code LLM TrainingSrishti Gureja, Elena Tommasone, Jingyi He, Sara Hooker, Matthias Gallé, and Marzieh FadaeeNov 2025
@misc{gureja2025verificationlimitscodellm, title = {Verification Limits Code LLM Training}, author = {Gureja, Srishti and Tommasone, Elena and He, Jingyi and Hooker, Sara and Gallé, Matthias and Fadaee, Marzieh}, year = {2025}, eprint = {2509.20837}, archiveprefix = {arXiv}, primaryclass = {cs.SE}, url = {https://arxiv.org/abs/2509.20837}, } - ArXivMaking, not Taking, the Best of NAmmar Khairi, Daniel D’souza, Marzieh Fadaee, and Julia KreutzerNov 2025
@misc{khairi2025makingtakingbestn, title = {Making, not Taking, the Best of N}, author = {Khairi, Ammar and D'souza, Daniel and Fadaee, Marzieh and Kreutzer, Julia}, year = {2025}, eprint = {2510.00931}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2510.00931}, } - ArXivThe Art of Asking: Multilingual Prompt Optimization for Synthetic DataDavid Mora, Viraat Aryabumi, Wei-Yin Ko, Sara Hooker, Julia Kreutzer, and Marzieh FadaeeNov 2025
@misc{mora2025artaskingmultilingualprompt, title = {The Art of Asking: Multilingual Prompt Optimization for Synthetic Data}, author = {Mora, David and Aryabumi, Viraat and Ko, Wei-Yin and Hooker, Sara and Kreutzer, Julia and Fadaee, Marzieh}, year = {2025}, eprint = {2510.19806}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2510.19806}, } - WMTFindings of the WMT25 Multilingual Instruction Shared Task: Persistent Hurdles in Reasoning, Generation, and EvaluationTom Kocmi, Sweta Agrawal, Ekaterina Artemova, Eleftherios Avramidis, Eleftheria Briakou, Pinzhen Chen, Marzieh Fadaee, Markus Freitag, Roman Grundkiewicz, Yupeng Hou, Philipp Koehn, Julia Kreutzer, Saab Mansour, Stefano Perrella, Lorenzo Proietti, Parker Riley, Eduardo Sánchez, Patricia Schmidtova, Mariya Shmatova, and Vilém ZouharIn Proceedings of the Tenth Conference on Machine Translation, Nov 2025
@inproceedings{kocmi-etal-2025-findings-wmt25, title = {Findings of the {WMT}25 Multilingual Instruction Shared Task: Persistent Hurdles in Reasoning, Generation, and Evaluation}, author = {Kocmi, Tom and Agrawal, Sweta and Artemova, Ekaterina and Avramidis, Eleftherios and Briakou, Eleftheria and Chen, Pinzhen and Fadaee, Marzieh and Freitag, Markus and Grundkiewicz, Roman and Hou, Yupeng and Koehn, Philipp and Kreutzer, Julia and Mansour, Saab and Perrella, Stefano and Proietti, Lorenzo and Riley, Parker and S{\'a}nchez, Eduardo and Schmidtova, Patricia and Shmatova, Mariya and Zouhar, Vil{\'e}m}, editor = {Haddow, Barry and Kocmi, Tom and Koehn, Philipp and Monz, Christof}, booktitle = {Proceedings of the Tenth Conference on Machine Translation}, month = nov, year = {2025}, address = {Suzhou, China}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2025.wmt-1.23/}, doi = {10.18653/v1/2025.wmt-1.23}, pages = {414--435}, isbn = {979-8-89176-341-8}, } - White paperScaling Language Data Ecosystems to Drive Industrial Development GrowthUnited Nations Development ProgrammeNov 2025
@misc{undplanguagedata2025scaling, title = {Scaling Language Data Ecosystems to Drive Industrial Development Growth}, author = {Programme, United Nations Development}, year = {2025}, url = {https://cdn.prod.website-files.com/66e31d90ea60e260f5ea025f/68546ed270a71196702c0081_Community%20Paper_Final%20for%20AI%20Hub%20Launch%20-%20REVISED%20VERSION%20(1).pdf}, } - ArXivNeoBabel: A Multilingual Open Tower for Visual GenerationMohammad Mahdi Derakhshani, Dheeraj Varghese, Marzieh Fadaee, and Cees G. M. SnoekNov 2025
@misc{derakhshani2025neobabelmultilingualopentower, title = {NeoBabel: A Multilingual Open Tower for Visual Generation}, author = {Derakhshani, Mohammad Mahdi and Varghese, Dheeraj and Fadaee, Marzieh and Snoek, Cees G. M.}, year = {2025}, eprint = {2507.06137}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2507.06137}, } - ArXivOne Tokenizer To Rule Them All: Emergent Language Plasticity via Multilingual TokenizersDiana Abagyan, Alejandro R. Salamanca, Andres Felipe Cruz-Salinas, Kris Cao, Hangyu Lin, Acyr Locatelli, Marzieh Fadaee, Ahmet Üstün, and Sara HookerNov 2025
@misc{abagyan2025tokenizerruleallemergent, title = {One Tokenizer To Rule Them All: Emergent Language Plasticity via Multilingual Tokenizers}, author = {Abagyan, Diana and Salamanca, Alejandro R. and Cruz-Salinas, Andres Felipe and Cao, Kris and Lin, Hangyu and Locatelli, Acyr and Fadaee, Marzieh and Üstün, Ahmet and Hooker, Sara}, year = {2025}, eprint = {2506.10766}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2506.10766}, } - ArXivThe State of Multilingual LLM Safety Research: From Measuring the Language Gap to Mitigating ItZheng-Xin Yong, Beyza Ermis, Marzieh Fadaee, Stephen H. Bach, and Julia KreutzerNov 2025
@misc{yong2025statemultilingualllmsafety, title = {The State of Multilingual LLM Safety Research: From Measuring the Language Gap to Mitigating It}, author = {Yong, Zheng-Xin and Ermis, Beyza and Fadaee, Marzieh and Bach, Stephen H. and Kreutzer, Julia}, year = {2025}, eprint = {2505.24119}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2505.24119}, } - ArXivThe Multilingual Divide and Its Impact on Global AI SafetyAidan Peppin, Julia Kreutzer, Alice Schoenauer Sebag, Kelly Marchisio, Beyza Ermis, John Dang, Samuel Cahyawijaya, Shivalika Singh, Seraphina Goldfarb-Tarrant, Viraat Aryabumi, Aakanksha, Wei-Yin Ko, Ahmet Üstün, Matthias Gallé, Marzieh Fadaee, and Sara HookerNov 2025
@misc{peppin2025multilingualdivideimpactglobal, title = {The Multilingual Divide and Its Impact on Global AI Safety}, author = {Peppin, Aidan and Kreutzer, Julia and Sebag, Alice Schoenauer and Marchisio, Kelly and Ermis, Beyza and Dang, John and Cahyawijaya, Samuel and Singh, Shivalika and Goldfarb-Tarrant, Seraphina and Aryabumi, Viraat and Aakanksha and Ko, Wei-Yin and Üstün, Ahmet and Gallé, Matthias and Fadaee, Marzieh and Hooker, Sara}, year = {2025}, eprint = {2505.21344}, archiveprefix = {arXiv}, primaryclass = {cs.AI}, url = {https://arxiv.org/abs/2505.21344}, } - ArXivReality Check: A New Evaluation Ecosystem Is Necessary to Understand AI’s Real World EffectsReva Schwartz, Rumman Chowdhury, Akash Kundu, Heather Frase, Marzieh Fadaee, Tom David, Gabriella Waters, Afaf Taik, Morgan Briggs, Patrick Hall, Shomik Jain, Kyra Yee, Spencer Thomas, Sundeep Bhandari, Qinghua Lu, Matthew Holmes, and Theodora SkeadasNov 2025
@misc{schwartz2025realitychecknewevaluation, title = {Reality Check: A New Evaluation Ecosystem Is Necessary to Understand AI's Real World Effects}, author = {Schwartz, Reva and Chowdhury, Rumman and Kundu, Akash and Frase, Heather and Fadaee, Marzieh and David, Tom and Waters, Gabriella and Taik, Afaf and Briggs, Morgan and Hall, Patrick and Jain, Shomik and Yee, Kyra and Thomas, Spencer and Bhandari, Sundeep and Lu, Qinghua and Holmes, Matthew and Skeadas, Theodora}, year = {2025}, eprint = {2505.18893}, archiveprefix = {arXiv}, primaryclass = {cs.CY}, url = {https://arxiv.org/abs/2505.18893}, } - ArXivAya Vision: Advancing the Frontier of Multilingual MultimodalitySaurabh Dash, Yiyang Nan, John Dang, Arash Ahmadian, Shivalika Singh, Madeline Smith, Bharat Venkitesh, Vlad Shmyhlo, Viraat Aryabumi, Walter Beller-Morales, Jeremy Pekmez, Jason Ozuzu, Pierre Richemond, Acyr Locatelli, Nick Frosst, Phil Blunsom, Aidan Gomez, Ivan Zhang, Marzieh Fadaee, Manoj Govindassamy, Sudip Roy, Matthias Gallé, Beyza Ermis, Ahmet Üstün, and Sara HookerNov 2025
@misc{dash2025ayavisionadvancingfrontier, title = {Aya Vision: Advancing the Frontier of Multilingual Multimodality}, author = {Dash, Saurabh and Nan, Yiyang and Dang, John and Ahmadian, Arash and Singh, Shivalika and Smith, Madeline and Venkitesh, Bharat and Shmyhlo, Vlad and Aryabumi, Viraat and Beller-Morales, Walter and Pekmez, Jeremy and Ozuzu, Jason and Richemond, Pierre and Locatelli, Acyr and Frosst, Nick and Blunsom, Phil and Gomez, Aidan and Zhang, Ivan and Fadaee, Marzieh and Govindassamy, Manoj and Roy, Sudip and Gallé, Matthias and Ermis, Beyza and Üstün, Ahmet and Hooker, Sara}, year = {2025}, eprint = {2505.08751}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2505.08751}, } - ArXivThe Leaderboard IllusionShivalika Singh, Yiyang Nan, Alex Wang, Daniel D’Souza, Sayash Kapoor, Ahmet Üstün, Sanmi Koyejo, Yuntian Deng, Shayne Longpre, Noah A. Smith, Beyza Ermis, Marzieh Fadaee, and Sara HookerNov 2025
@misc{singh2025leaderboardillusion, title = {The Leaderboard Illusion}, author = {Singh, Shivalika and Nan, Yiyang and Wang, Alex and D'Souza, Daniel and Kapoor, Sayash and Üstün, Ahmet and Koyejo, Sanmi and Deng, Yuntian and Longpre, Shayne and Smith, Noah A. and Ermis, Beyza and Fadaee, Marzieh and Hooker, Sara}, year = {2025}, eprint = {2504.20879}, archiveprefix = {arXiv}, primaryclass = {cs.AI}, url = {https://arxiv.org/abs/2504.20879}, } - ArXivA Post-trainer’s Guide to Multilingual Training Data: Uncovering Cross-lingual Transfer DynamicsLuisa Shimabucoro, Ahmet Ustun, Marzieh Fadaee, and Sebastian RuderNov 2025
@misc{shimabucoro2025posttrainersguidemultilingualtraining, title = {A Post-trainer's Guide to Multilingual Training Data: Uncovering Cross-lingual Transfer Dynamics}, author = {Shimabucoro, Luisa and Ustun, Ahmet and Fadaee, Marzieh and Ruder, Sebastian}, year = {2025}, eprint = {2504.16677}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2504.16677}, } - ArXivDéjà Vu: Multilingual LLM Evaluation through the Lens of Machine Translation EvaluationJulia Kreutzer, Eleftheria Briakou, Sweta Agrawal, Marzieh Fadaee, and Kocmi TomNov 2025
@misc{kreutzer2025dejavumultilingualllm, title = {D\'ej\`a Vu: Multilingual LLM Evaluation through the Lens of Machine Translation Evaluation}, author = {Kreutzer, Julia and Briakou, Eleftheria and Agrawal, Sweta and Fadaee, Marzieh and Tom, Kocmi}, year = {2025}, eprint = {2504.11829}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2504.11829}, } - ArXivKaleidoscope: In-language Exams for Massively Multilingual Vision EvaluationIsrafel Salazar, Manuel Fernández Burda, Shayekh Bin Islam, Arshia Soltani Moakhar, Shivalika Singh, Fabian Farestam, Angelika Romanou, Danylo Boiko, Dipika Khullar, Mike Zhang, Dominik Krzemiński, Jekaterina Novikova, Luísa Shimabucoro, Joseph Marvin Imperial, Rishabh Maheshwary, Sharad Duwal, Alfonso Amayuelas, Swati Rajwal, Jebish Purbey, Ahmed Ruby, Nicholas Popovič, Marek Suppa, Azmine Toushik Wasi, Ram Mohan Rao Kadiyala, Olga Tsymboi, Maksim Kostritsya, Bardia Soltani Moakhar, Gabriel Costa Merlin, Otávio Ferracioli Coletti, Maral Jabbari Shiviari, MohammadAmin fard, Silvia Fernandez, María Grandury, Dmitry Abulkhanov, Drishti Sharma, Andre Guarnier De Mitri, Leticia Bossatto Marchezi, Setayesh Heydari, Johan Obando-Ceron, Nazar Kohut, Beyza Ermis, Desmond Elliott, Enzo Ferrante, Sara Hooker, and Marzieh FadaeeNov 2025
@misc{salazar2025kaleidoscopeinlanguageexamsmassively, title = {Kaleidoscope: In-language Exams for Massively Multilingual Vision Evaluation}, author = {Salazar, Israfel and Burda, Manuel Fernández and Islam, Shayekh Bin and Moakhar, Arshia Soltani and Singh, Shivalika and Farestam, Fabian and Romanou, Angelika and Boiko, Danylo and Khullar, Dipika and Zhang, Mike and Krzemiński, Dominik and Novikova, Jekaterina and Shimabucoro, Luísa and Imperial, Joseph Marvin and Maheshwary, Rishabh and Duwal, Sharad and Amayuelas, Alfonso and Rajwal, Swati and Purbey, Jebish and Ruby, Ahmed and Popovič, Nicholas and Suppa, Marek and Wasi, Azmine Toushik and Kadiyala, Ram Mohan Rao and Tsymboi, Olga and Kostritsya, Maksim and Moakhar, Bardia Soltani and da Costa Merlin, Gabriel and Coletti, Otávio Ferracioli and Shiviari, Maral Jabbari and farahani fard, MohammadAmin and Fernandez, Silvia and Grandury, María and Abulkhanov, Dmitry and Sharma, Drishti and Mitri, Andre Guarnier De and Marchezi, Leticia Bossatto and Heydari, Setayesh and Obando-Ceron, Johan and Kohut, Nazar and Ermis, Beyza and Elliott, Desmond and Ferrante, Enzo and Hooker, Sara and Fadaee, Marzieh}, year = {2025}, eprint = {2504.07072}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2504.07072}, } - ArXivCommand A: An Enterprise-Ready Large Language ModelTeam Cohere, Aakanksha, Arash Ahmadian, Marwan Ahmed, Jay Alammar, Milad Alizadeh, Yazeed Alnumay, Sophia Althammer, Arkady Arkhangorodsky, Viraat Aryabumi, Dennis Aumiller, Raphaël Avalos, Zahara Aviv, Sammie Bae, Saurabh Baji, Alexandre Barbet, Max Bartolo, Björn Bebensee, Neeral Beladia, Walter Beller-Morales, Alexandre Bérard, Andrew Berneshawi, Anna Bialas, Phil Blunsom, Matt Bobkin, Adi Bongale, Sam Braun, Maxime Brunet, Samuel Cahyawijaya, David Cairuz, Jon Ander Campos, Cassie Cao, Kris Cao, Roman Castagné, Julián Cendrero, Leila Chan Currie, Yash Chandak, Diane Chang, Giannis Chatziveroglou, Hongyu Chen, Claire Cheng, Alexis Chevalier, Justin T. Chiu, Eugene Cho, Eugene Choi, Eujeong Choi, Tim Chung, Volkan Cirik, Ana Cismaru, Pierre Clavier, Henry Conklin, Lucas Crawhall-Stein, Devon Crouse, Andres Felipe Cruz-Salinas, Ben Cyrus, Daniel D’souza, Hugo Dalla-Torre, John Dang, William Darling, Omar Darwiche Domingues, Saurabh Dash, Antoine Debugne, Théo Dehaze, Shaan Desai, Joan Devassy, Rishit Dholakia, Kyle Duffy, Ali Edalati, Ace Eldeib, Abdullah Elkady, Sarah Elsharkawy, Irem Ergün, Beyza Ermis, Marzieh Fadaee, Boyu Fan, Lucas Fayoux, Yannis Flet-Berliac, Nick Frosst, Matthias Gallé, Wojciech Galuba, Utsav Garg, Matthieu Geist, Mohammad Gheshlaghi Azar, Ellen Gilsenan-McMahon, Seraphina Goldfarb-Tarrant, Tomas Goldsack, Aidan Gomez, Victor Machado Gonzaga, Nithya Govindarajan, Manoj Govindassamy, Nathan Grinsztajn, Nikolas Gritsch, Patrick Gu, Shangmin Guo, Kilian Haefeli, Rod Hajjar, Tim Hawes, Jingyi He, Sebastian Hofstätter, Sungjin Hong, Sara Hooker, Tom Hosking, Stephanie Howe, Eric Hu, Renjie Huang, Hemant Jain, Ritika Jain, Nick Jakobi, Madeline Jenkins, JJ Jordan, Dhruti Joshi, Jason Jung, Trushant Kalyanpur, Siddhartha Rao Kamalakara, Julia Kedrzycki, Gokce Keskin, Edward Kim, Joon Kim, Wei-Yin Ko, Tom Kocmi, Michael Kozakov, Wojciech Kryściński, Arnav Kumar Jain, Komal Kumar Teru, Sander Land, Michael Lasby, Olivia Lasche, Justin Lee, Patrick Lewis, Jeffrey Li, Jonathan Li, Hangyu Lin, Acyr Locatelli, Kevin Luong, Raymond Ma, Lukáš Mach, Marina Machado, Joanne Magbitang, Brenda Malacara Lopez, Aryan Mann, Kelly Marchisio, Olivia Markham, Alexandre Matton, Alex McKinney, Dominic McLoughlin, Jozef Mokry, Adrien Morisot, Autumn Moulder, Harry Moynehan, Maximilian Mozes, Vivek Muppalla, Lidiya Murakhovska, Hemangani Nagarajan, Alekhya Nandula, Hisham Nasir, Shauna Nehra, Josh Netto-Rosen, Daniel Ohashi, James Owers-Bardsley, Jason Ozuzu, Dennis Padilla, Gloria Park, Sam Passaglia, Jeremy Pekmez, Laura Penstone, Aleksandra Piktus, Case Ploeg, Andrew Poulton, Youran Qi, Shubha Raghvendra, Miguel Ramos, Ekagra Ranjan, Pierre Richemond, Cécile Robert-Michon, Aurélien Rodriguez, Sudip Roy, Sebastian Ruder, Laura Ruis, Louise Rust, Anubhav Sachan, Alejandro Salamanca, Kailash Karthik Saravanakumar, Isha Satyakam, Alice Schoenauer Sebag, Priyanka Sen, Sholeh Sepehri, Preethi Seshadri, Ye Shen, Tom Sherborne, Sylvie Shang Shi, Sanal Shivaprasad, Vladyslav Shmyhlo, Anirudh Shrinivason, Inna Shteinbuk, Amir Shukayev, Mathieu Simard, Ella Snyder, Ava Spataru, Victoria Spooner, Trisha Starostina, Florian Strub, Yixuan Su, Jimin Sun, Dwarak Talupuru, Eugene Tarassov, Elena Tommasone, Jennifer Tracey, Billy Trend, Evren Tumer, Ahmet Üstün, Bharat Venkitesh, David Venuto, Pat Verga, Maxime Voisin, Alex Wang, Donglu Wang, Shijian Wang, Edmond Wen, Naomi White, Jesse Willman, Marysia Winkels, Chen Xia, Jessica Xie, Minjie Xu, Bowen Yang, Tan Yi-Chern, Ivan Zhang, Zhenyu Zhao, and Zhoujie ZhaoNov 2025
@misc{cohere2025commandaenterprisereadylarge, title = {Command A: An Enterprise-Ready Large Language Model}, author = {Cohere, Team and Aakanksha and Ahmadian, Arash and Ahmed, Marwan and Alammar, Jay and Alizadeh, Milad and Alnumay, Yazeed and Althammer, Sophia and Arkhangorodsky, Arkady and Aryabumi, Viraat and Aumiller, Dennis and Avalos, Raphaël and Aviv, Zahara and Bae, Sammie and Baji, Saurabh and Barbet, Alexandre and Bartolo, Max and Bebensee, Björn and Beladia, Neeral and Beller-Morales, Walter and Bérard, Alexandre and Berneshawi, Andrew and Bialas, Anna and Blunsom, Phil and Bobkin, Matt and Bongale, Adi and Braun, Sam and Brunet, Maxime and Cahyawijaya, Samuel and Cairuz, David and Campos, Jon Ander and Cao, Cassie and Cao, Kris and Castagné, Roman and Cendrero, Julián and Currie, Leila Chan and Chandak, Yash and Chang, Diane and Chatziveroglou, Giannis and Chen, Hongyu and Cheng, Claire and Chevalier, Alexis and Chiu, Justin T. and Cho, Eugene and Choi, Eugene and Choi, Eujeong and Chung, Tim and Cirik, Volkan and Cismaru, Ana and Clavier, Pierre and Conklin, Henry and Crawhall-Stein, Lucas and Crouse, Devon and Cruz-Salinas, Andres Felipe and Cyrus, Ben and D'souza, Daniel and Dalla-Torre, Hugo and Dang, John and Darling, William and Domingues, Omar Darwiche and Dash, Saurabh and Debugne, Antoine and Dehaze, Théo and Desai, Shaan and Devassy, Joan and Dholakia, Rishit and Duffy, Kyle and Edalati, Ali and Eldeib, Ace and Elkady, Abdullah and Elsharkawy, Sarah and Ergün, Irem and Ermis, Beyza and Fadaee, Marzieh and Fan, Boyu and Fayoux, Lucas and Flet-Berliac, Yannis and Frosst, Nick and Gallé, Matthias and Galuba, Wojciech and Garg, Utsav and Geist, Matthieu and Azar, Mohammad Gheshlaghi and Gilsenan-McMahon, Ellen and Goldfarb-Tarrant, Seraphina and Goldsack, Tomas and Gomez, Aidan and Gonzaga, Victor Machado and Govindarajan, Nithya and Govindassamy, Manoj and Grinsztajn, Nathan and Gritsch, Nikolas and Gu, Patrick and Guo, Shangmin and Haefeli, Kilian and Hajjar, Rod and Hawes, Tim and He, Jingyi and Hofstätter, Sebastian and Hong, Sungjin and Hooker, Sara and Hosking, Tom and Howe, Stephanie and Hu, Eric and Huang, Renjie and Jain, Hemant and Jain, Ritika and Jakobi, Nick and Jenkins, Madeline and Jordan, JJ and Joshi, Dhruti and Jung, Jason and Kalyanpur, Trushant and Kamalakara, Siddhartha Rao and Kedrzycki, Julia and Keskin, Gokce and Kim, Edward and Kim, Joon and Ko, Wei-Yin and Kocmi, Tom and Kozakov, Michael and Kryściński, Wojciech and Jain, Arnav Kumar and Teru, Komal Kumar and Land, Sander and Lasby, Michael and Lasche, Olivia and Lee, Justin and Lewis, Patrick and Li, Jeffrey and Li, Jonathan and Lin, Hangyu and Locatelli, Acyr and Luong, Kevin and Ma, Raymond and Mach, Lukáš and Machado, Marina and Magbitang, Joanne and Lopez, Brenda Malacara and Mann, Aryan and Marchisio, Kelly and Markham, Olivia and Matton, Alexandre and McKinney, Alex and McLoughlin, Dominic and Mokry, Jozef and Morisot, Adrien and Moulder, Autumn and Moynehan, Harry and Mozes, Maximilian and Muppalla, Vivek and Murakhovska, Lidiya and Nagarajan, Hemangani and Nandula, Alekhya and Nasir, Hisham and Nehra, Shauna and Netto-Rosen, Josh and Ohashi, Daniel and Owers-Bardsley, James and Ozuzu, Jason and Padilla, Dennis and Park, Gloria and Passaglia, Sam and Pekmez, Jeremy and Penstone, Laura and Piktus, Aleksandra and Ploeg, Case and Poulton, Andrew and Qi, Youran and Raghvendra, Shubha and Ramos, Miguel and Ranjan, Ekagra and Richemond, Pierre and Robert-Michon, Cécile and Rodriguez, Aurélien and Roy, Sudip and Ruder, Sebastian and Ruis, Laura and Rust, Louise and Sachan, Anubhav and Salamanca, Alejandro and Saravanakumar, Kailash Karthik and Satyakam, Isha and Sebag, Alice Schoenauer and Sen, Priyanka and Sepehri, Sholeh and Seshadri, Preethi and Shen, Ye and Sherborne, Tom and Shi, Sylvie Shang and Shivaprasad, Sanal and Shmyhlo, Vladyslav and Shrinivason, Anirudh and Shteinbuk, Inna and Shukayev, Amir and Simard, Mathieu and Snyder, Ella and Spataru, Ava and Spooner, Victoria and Starostina, Trisha and Strub, Florian and Su, Yixuan and Sun, Jimin and Talupuru, Dwarak and Tarassov, Eugene and Tommasone, Elena and Tracey, Jennifer and Trend, Billy and Tumer, Evren and Üstün, Ahmet and Venkitesh, Bharat and Venuto, David and Verga, Pat and Voisin, Maxime and Wang, Alex and Wang, Donglu and Wang, Shijian and Wen, Edmond and White, Naomi and Willman, Jesse and Winkels, Marysia and Xia, Chen and Xie, Jessica and Xu, Minjie and Yang, Bowen and Yi-Chern, Tan and Zhang, Ivan and Zhao, Zhenyu and Zhao, Zhoujie}, year = {2025}, eprint = {2504.00698}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2504.00698}, } - ACLFrom Tools to Teammates: Evaluating LLMs in Multi-Session Coding InteractionsNathanaël Carraz Rakotonirina, Mohammed Hamdy, Jon Ander Campos, Lucas Weber, Alberto Testoni, Marzieh Fadaee, Sandro Pezzelle, and Marco Del TrediciNov 2025
@misc{rakotonirina2025toolsteammatesevaluatingllms, title = {From Tools to Teammates: Evaluating LLMs in Multi-Session Coding Interactions}, author = {Rakotonirina, Nathanaël Carraz and Hamdy, Mohammed and Campos, Jon Ander and Weber, Lucas and Testoni, Alberto and Fadaee, Marzieh and Pezzelle, Sandro and Tredici, Marco Del}, year = {2025}, eprint = {2502.13791}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2502.13791}, } - ArXivTowards Best Practices for Open Datasets for LLM TrainingStefan Baack, Stella Biderman, Kasia Odrozek, Aviya Skowron, Ayah Bdeir, Jillian Bommarito, Jennifer Ding, Maximilian Gahntz, Paul Keller, Pierre-Carl Langlais, Greg Lindahl, Sebastian Majstorovic, Nik Marda, Guilherme Penedo, Maarten Van Segbroeck, Jennifer Wang, Leandro Werra, Mitchell Baker, Julie Belião, Kasia Chmielinski, Marzieh Fadaee, Lisa Gutermuth, Hynek Kydlíček, Greg Leppert, EM Lewis-Jong, Solana Larsen, Shayne Longpre, Angela Oduor Lungati, Cullen Miller, Victor Miller, Max Ryabinin, Kathleen Siminyu, Andrew Strait, Mark Surman, Anna Tumadóttir, Maurice Weber, Rebecca Weiss, Lee White, and Thomas WolfNov 2025
@misc{baack2025bestpracticesopendatasets, title = {Towards Best Practices for Open Datasets for LLM Training}, author = {Baack, Stefan and Biderman, Stella and Odrozek, Kasia and Skowron, Aviya and Bdeir, Ayah and Bommarito, Jillian and Ding, Jennifer and Gahntz, Maximilian and Keller, Paul and Langlais, Pierre-Carl and Lindahl, Greg and Majstorovic, Sebastian and Marda, Nik and Penedo, Guilherme and Segbroeck, Maarten Van and Wang, Jennifer and von Werra, Leandro and Baker, Mitchell and Belião, Julie and Chmielinski, Kasia and Fadaee, Marzieh and Gutermuth, Lisa and Kydlíček, Hynek and Leppert, Greg and Lewis-Jong, EM and Larsen, Solana and Longpre, Shayne and Lungati, Angela Oduor and Miller, Cullen and Miller, Victor and Ryabinin, Max and Siminyu, Kathleen and Strait, Andrew and Surman, Mark and Tumadóttir, Anna and Weber, Maurice and Weiss, Rebecca and White, Lee and Wolf, Thomas}, year = {2025}, eprint = {2501.08365}, archiveprefix = {arXiv}, primaryclass = {cs.CY}, url = {https://arxiv.org/abs/2501.08365}, } - ICLRINCLUDE: Evaluating Multilingual Language Understanding with Regional KnowledgeAngelika Romanou, Negar Foroutan, Anna Sotnikova, Sree Harsha Nelaturu, Shivalika Singh, Rishabh Maheshwary, Micol Altomare, Zeming Chen, Mohamed A. Haggag, Snegha A, Alfonso Amayuelas, Azril Hafizi Amirudin, Danylo Boiko, Michael Chang, Jenny Chim, Gal Cohen, Aditya Kumar Dalmia, Abraham Diress, Sharad Duwal, Daniil Dzenhaliou, Daniel Fernando Erazo Florez, Fabian Farestam, Joseph Marvin Imperial, Shayekh Bin Islam, Perttu Isotalo, Maral Jabbarishiviari, Börje F. Karlsson, Eldar Khalilov, Christopher Klamm, Fajri Koto, Dominik Krzemiński, Gabriel Adriano Melo, Syrielle Montariol, Yiyang Nan, Joel Niklaus, Jekaterina Novikova, Johan Samir Obando Ceron, Debjit Paul, Esther Ploeger, Jebish Purbey, Swati Rajwal, Selvan Sunitha Ravi, Sara Rydell, Roshan Santhosh, Drishti Sharma, Marjana Prifti Skenduli, Arshia Soltani Moakhar, Bardia moakhar, Ayush Kumar Tarun, Azmine Toushik Wasi, Thenuka Ovin Weerasinghe, Serhan Yilmaz, Mike Zhang, Imanol Schlag, Marzieh Fadaee, Sara Hooker, and Antoine BosselutIn The Thirteenth International Conference on Learning Representations, Nov 2025
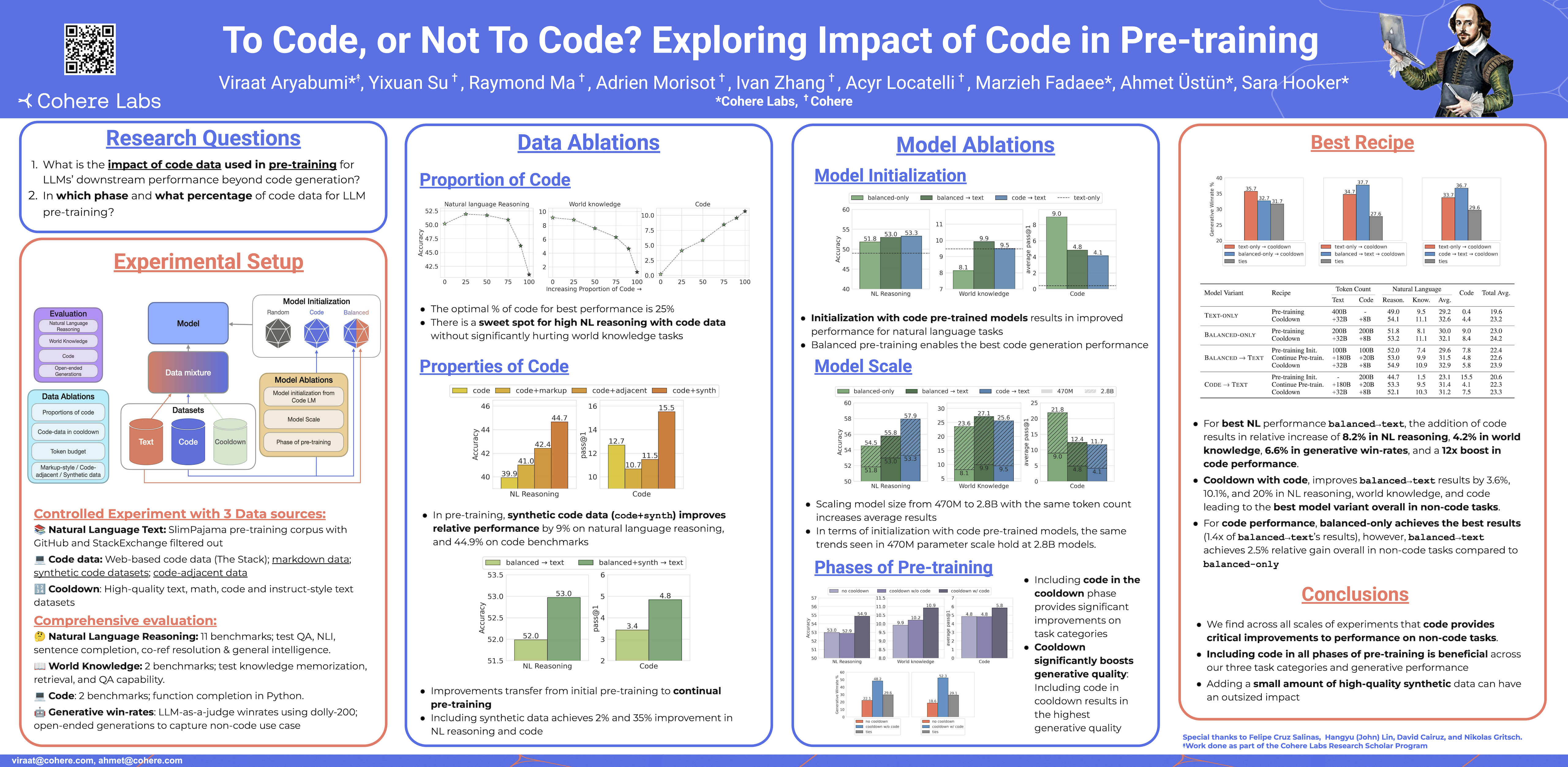
@inproceedings{romanou2025include, title = {{INCLUDE}: Evaluating Multilingual Language Understanding with Regional Knowledge}, author = {Romanou, Angelika and Foroutan, Negar and Sotnikova, Anna and Nelaturu, Sree Harsha and Singh, Shivalika and Maheshwary, Rishabh and Altomare, Micol and Chen, Zeming and Haggag, Mohamed A. and A, Snegha and Amayuelas, Alfonso and Amirudin, Azril Hafizi and Boiko, Danylo and Chang, Michael and Chim, Jenny and Cohen, Gal and Dalmia, Aditya Kumar and Diress, Abraham and Duwal, Sharad and Dzenhaliou, Daniil and Florez, Daniel Fernando Erazo and Farestam, Fabian and Imperial, Joseph Marvin and Islam, Shayekh Bin and Isotalo, Perttu and Jabbarishiviari, Maral and Karlsson, B{\"o}rje F. and Khalilov, Eldar and Klamm, Christopher and Koto, Fajri and Krzemi{\'n}ski, Dominik and de Melo, Gabriel Adriano and Montariol, Syrielle and Nan, Yiyang and Niklaus, Joel and Novikova, Jekaterina and Ceron, Johan Samir Obando and Paul, Debjit and Ploeger, Esther and Purbey, Jebish and Rajwal, Swati and Ravi, Selvan Sunitha and Rydell, Sara and Santhosh, Roshan and Sharma, Drishti and Skenduli, Marjana Prifti and Moakhar, Arshia Soltani and soltani moakhar, Bardia and Tarun, Ayush Kumar and Wasi, Azmine Toushik and Weerasinghe, Thenuka Ovin and Yilmaz, Serhan and Zhang, Mike and Schlag, Imanol and Fadaee, Marzieh and Hooker, Sara and Bosselut, Antoine}, booktitle = {The Thirteenth International Conference on Learning Representations}, year = {2025}, url = {https://openreview.net/forum?id=k3gCieTXeY}, } - ICLRTo Code or Not To Code? Exploring Impact of Code in Pre-trainingViraat Aryabumi, Yixuan Su, Raymond Ma, Adrien Morisot, Ivan Zhang, Acyr Locatelli, Marzieh Fadaee, Ahmet Üstün, and Sara HookerIn The Thirteenth International Conference on Learning Representations, Nov 2025
@inproceedings{aryabumi2025to, title = {To Code or Not To Code? Exploring Impact of Code in Pre-training}, author = {Aryabumi, Viraat and Su, Yixuan and Ma, Raymond and Morisot, Adrien and Zhang, Ivan and Locatelli, Acyr and Fadaee, Marzieh and {\"U}st{\"u}n, Ahmet and Hooker, Sara}, booktitle = {The Thirteenth International Conference on Learning Representations}, year = {2025}, url = {https://openreview.net/forum?id=zSfeN1uAcx}, }
{kind=link}
2024
- ArXivAya Expanse: Combining Research Breakthroughs for a New Multilingual FrontierJohn Dang, Shivalika Singh, Daniel D’souza, Arash Ahmadian, Alejandro Salamanca, Madeline Smith, Aidan Peppin, Sungjin Hong, Manoj Govindassamy, Terrence Zhao, Sandra Kublik, Meor Amer, Viraat Aryabumi, Jon Ander Campos, Yi-Chern Tan, Tom Kocmi, Florian Strub, Nathan Grinsztajn, Yannis Flet-Berliac, Acyr Locatelli, Hangyu Lin, Dwarak Talupuru, Bharat Venkitesh, David Cairuz, Bowen Yang, Tim Chung, Wei-Yin Ko, Sylvie Shang Shi, Amir Shukayev, Sammie Bae, Aleksandra Piktus, Roman Castagné, Felipe Cruz-Salinas, Eddie Kim, Lucas Crawhall-Stein, Adrien Morisot, Sudip Roy, Phil Blunsom, Ivan Zhang, Aidan Gomez, Nick Frosst, Marzieh Fadaee, Beyza Ermis, Ahmet Üstün, and Sara HookerNov 2024
@misc{dang2024ayaexpansecombiningresearch, title = {Aya Expanse: Combining Research Breakthroughs for a New Multilingual Frontier}, author = {Dang, John and Singh, Shivalika and D'souza, Daniel and Ahmadian, Arash and Salamanca, Alejandro and Smith, Madeline and Peppin, Aidan and Hong, Sungjin and Govindassamy, Manoj and Zhao, Terrence and Kublik, Sandra and Amer, Meor and Aryabumi, Viraat and Campos, Jon Ander and Tan, Yi-Chern and Kocmi, Tom and Strub, Florian and Grinsztajn, Nathan and Flet-Berliac, Yannis and Locatelli, Acyr and Lin, Hangyu and Talupuru, Dwarak and Venkitesh, Bharat and Cairuz, David and Yang, Bowen and Chung, Tim and Ko, Wei-Yin and Shi, Sylvie Shang and Shukayev, Amir and Bae, Sammie and Piktus, Aleksandra and Castagné, Roman and Cruz-Salinas, Felipe and Kim, Eddie and Crawhall-Stein, Lucas and Morisot, Adrien and Roy, Sudip and Blunsom, Phil and Zhang, Ivan and Gomez, Aidan and Frosst, Nick and Fadaee, Marzieh and Ermis, Beyza and Üstün, Ahmet and Hooker, Sara}, year = {2024}, eprint = {2412.04261}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2412.04261}, } - ACLGlobal MMLU: Understanding and Addressing Cultural and Linguistic Biases in Multilingual EvaluationShivalika Singh, Angelika Romanou, Clémentine Fourrier, David I. Adelani, Jian Gang Ngui, Daniel Vila-Suero, Peerat Limkonchotiwat, Kelly Marchisio, Wei Qi Leong, Yosephine Susanto, Raymond Ng, Shayne Longpre, Wei-Yin Ko, Madeline Smith, Antoine Bosselut, Alice Oh, Andre F. T. Martins, Leshem Choshen, Daphne Ippolito, Enzo Ferrante, Marzieh Fadaee, Beyza Ermis, and Sara HookerNov 2024
@misc{singh2024globalmmluunderstandingaddressing, title = {Global MMLU: Understanding and Addressing Cultural and Linguistic Biases in Multilingual Evaluation}, author = {Singh, Shivalika and Romanou, Angelika and Fourrier, Clémentine and Adelani, David I. and Ngui, Jian Gang and Vila-Suero, Daniel and Limkonchotiwat, Peerat and Marchisio, Kelly and Leong, Wei Qi and Susanto, Yosephine and Ng, Raymond and Longpre, Shayne and Ko, Wei-Yin and Smith, Madeline and Bosselut, Antoine and Oh, Alice and Martins, Andre F. T. and Choshen, Leshem and Ippolito, Daphne and Ferrante, Enzo and Fadaee, Marzieh and Ermis, Beyza and Hooker, Sara}, year = {2024}, eprint = {2412.03304}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2412.03304}, } - ACLM-RewardBench: Evaluating Reward Models in Multilingual SettingsSrishti Gureja, Lester James V. Miranda, Shayekh Bin Islam, Rishabh Maheshwary, Drishti Sharma, Gusti Winata, Nathan Lambert, Sebastian Ruder, Sara Hooker, and Marzieh FadaeeNov 2024
@misc{gureja2024mrewardbenchevaluatingrewardmodels, title = {M-RewardBench: Evaluating Reward Models in Multilingual Settings}, author = {Gureja, Srishti and Miranda, Lester James V. and Islam, Shayekh Bin and Maheshwary, Rishabh and Sharma, Drishti and Winata, Gusti and Lambert, Nathan and Ruder, Sebastian and Hooker, Sara and Fadaee, Marzieh}, year = {2024}, eprint = {2410.15522}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2410.15522}, } - Neurips WokshopMix Data or Merge Models? Optimizing for Diverse Multi-Task LearningAakanksha, Arash Ahmadian, Seraphina Goldfarb-Tarrant, Beyza Ermis, Marzieh Fadaee, and Sara HookerNov 2024
@misc{aakanksha2024mixdatamergemodels, title = {Mix Data or Merge Models? Optimizing for Diverse Multi-Task Learning}, author = {Aakanksha and Ahmadian, Arash and Goldfarb-Tarrant, Seraphina and Ermis, Beyza and Fadaee, Marzieh and Hooker, Sara}, year = {2024}, eprint = {2410.10801}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2410.10801}, } - ICML workshopDiversify and Conquer: Diversity-Centric Data Selection with Iterative RefinementSimon Yu, Liangyu Chen, Sara Ahmadian, and Marzieh FadaeeNov 2024
@misc{yu2024diversifyconquerdiversitycentricdata, title = {Diversify and Conquer: Diversity-Centric Data Selection with Iterative Refinement}, author = {Yu, Simon and Chen, Liangyu and Ahmadian, Sara and Fadaee, Marzieh}, year = {2024}, eprint = {2409.11378}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2409.11378}, } - EMNLPLLM See, LLM Do: Leveraging Active Inheritance to Target Non-Differentiable ObjectivesIn Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Nov 2024
The widespread adoption of synthetic data raises new questions about how models generating the data can influence other large language models (LLMs). To start, our work exhaustively characterizes the impact of passive inheritance of model properties by systematically studying how the source of synthetic data shapes models’ internal biases, calibration and preferences, and their generations’ textual attributes, providing one of the most comprehensive studies to-date. We find that models are surprisingly sensitive towards certain attributes even when the synthetic data prompts appear “neutral” which invites the question: can we explicitly steer the distilled data towards desired properties? We demonstrate how such active inheritance can steer the generation profiles of models towards desirable non-differentiable attributes in both directions, e.g. increasing lexical diversity or reducing toxicity. Overall, our study broadens the understanding of the implicit biases inherited by LLMs and explores how we can leverage them to positive effect.
@inproceedings{shimabucoro-etal-2024-llm, title = {{LLM} See, {LLM} Do: Leveraging Active Inheritance to Target Non-Differentiable Objectives}, author = {Shimabucoro, Lu{\'i}sa and Ruder, Sebastian and Kreutzer, Julia and Fadaee, Marzieh and Hooker, Sara}, editor = {Al-Onaizan, Yaser and Bansal, Mohit and Chen, Yun-Nung}, booktitle = {Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing}, month = nov, year = {2024}, address = {Miami, Florida, USA}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.emnlp-main.521/}, doi = {10.18653/v1/2024.emnlp-main.521}, pages = {9243--9267}, } - EMNLPThe Multilingual Alignment Prism: Aligning Global and Local Preferences to Reduce HarmAakanksha, Arash Ahmadian, Beyza Ermis, Seraphina Goldfarb-Tarrant, Julia Kreutzer, Marzieh Fadaee, and Sara HookerIn Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Nov 2024
@inproceedings{aakanksha-etal-2024-multilingual, title = {The Multilingual Alignment Prism: Aligning Global and Local Preferences to Reduce Harm}, author = {Aakanksha and Ahmadian, Arash and Ermis, Beyza and Goldfarb-Tarrant, Seraphina and Kreutzer, Julia and Fadaee, Marzieh and Hooker, Sara}, editor = {Al-Onaizan, Yaser and Bansal, Mohit and Chen, Yun-Nung}, booktitle = {Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing}, month = nov, year = {2024}, address = {Miami, Florida, USA}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.emnlp-main.671/}, doi = {10.18653/v1/2024.emnlp-main.671}, pages = {12027--12049}, } - ArXivAya 23: Open Weight Releases to Further Multilingual ProgressViraat Aryabumi, John Dang, Dwarak Talupuru, Saurabh Dash, David Cairuz, Hangyu Lin, Bharat Venkitesh, Madeline Smith, Jon Ander Campos, Yi Chern Tan, Kelly Marchisio, Max Bartolo, Sebastian Ruder, Acyr Locatelli, Julia Kreutzer, Nick Frosst, Aidan Gomez, Phil Blunsom, Marzieh Fadaee, Ahmet Üstün, and Sara HookerNov 2024
@misc{aryabumi2024aya23openweight, title = {Aya 23: Open Weight Releases to Further Multilingual Progress}, author = {Aryabumi, Viraat and Dang, John and Talupuru, Dwarak and Dash, Saurabh and Cairuz, David and Lin, Hangyu and Venkitesh, Bharat and Smith, Madeline and Campos, Jon Ander and Tan, Yi Chern and Marchisio, Kelly and Bartolo, Max and Ruder, Sebastian and Locatelli, Acyr and Kreutzer, Julia and Frosst, Nick and Gomez, Aidan and Blunsom, Phil and Fadaee, Marzieh and Üstün, Ahmet and Hooker, Sara}, year = {2024}, eprint = {2405.15032}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2405.15032}, } - ACLBack to Basics: Revisiting REINFORCE-Style Optimization for Learning from Human Feedback in LLMsArash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara HookerIn Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Aug 2024
@inproceedings{ahmadian-etal-2024-back, title = {Back to Basics: Revisiting {REINFORCE}-Style Optimization for Learning from Human Feedback in {LLM}s}, author = {Ahmadian, Arash and Cremer, Chris and Gall{\'e}, Matthias and Fadaee, Marzieh and Kreutzer, Julia and Pietquin, Olivier and {\"U}st{\"u}n, Ahmet and Hooker, Sara}, editor = {Ku, Lun-Wei and Martins, Andre and Srikumar, Vivek}, booktitle = {Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)}, month = aug, year = {2024}, address = {Bangkok, Thailand}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.acl-long.662/}, doi = {10.18653/v1/2024.acl-long.662}, pages = {12248--12267}, } - ACLBack to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMsArash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Ahmet Üstün, and Sara HookerAug 2024
@misc{ahmadian2024basics, title = {Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs}, author = {Ahmadian, Arash and Cremer, Chris and Gallé, Matthias and Fadaee, Marzieh and Kreutzer, Julia and Üstün, Ahmet and Hooker, Sara}, year = {2024}, eprint = {2402.14740}, archiveprefix = {arXiv}, primaryclass = {cs.LG}, url = {https://arxiv.org/abs/2402.14740}, } - ACLAya Model: An Instruction Finetuned Open-Access Multilingual Language ModelAhmet Üstün, Viraat Aryabumi, Zheng Yong, Wei-Yin Ko, Daniel D’souza, Gbemileke Onilude, Neel Bhandari, Shivalika Singh, Hui-Lee Ooi, Amr Kayid, Freddie Vargus, Phil Blunsom, Shayne Longpre, Niklas Muennighoff, Marzieh Fadaee, Julia Kreutzer, and Sara HookerIn Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Aug 2024
Best paper award
@inproceedings{ustun-etal-2024-aya, title = {Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model}, author = {{\"U}st{\"u}n, Ahmet and Aryabumi, Viraat and Yong, Zheng and Ko, Wei-Yin and D{'}souza, Daniel and Onilude, Gbemileke and Bhandari, Neel and Singh, Shivalika and Ooi, Hui-Lee and Kayid, Amr and Vargus, Freddie and Blunsom, Phil and Longpre, Shayne and Muennighoff, Niklas and Fadaee, Marzieh and Kreutzer, Julia and Hooker, Sara}, editor = {Ku, Lun-Wei and Martins, Andre and Srikumar, Vivek}, booktitle = {Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)}, month = aug, year = {2024}, address = {Bangkok, Thailand}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.acl-long.845/}, doi = {10.18653/v1/2024.acl-long.845}, pages = {15894--15939}, } - ACLAya Dataset: An Open-Access Collection for Multilingual Instruction TuningShivalika Singh, Freddie Vargus, Daniel D’souza, Börje Karlsson, Abinaya Mahendiran, Wei-Yin Ko, Herumb Shandilya, Jay Patel, Deividas Mataciunas, Laura O’Mahony, Mike Zhang, Ramith Hettiarachchi, Joseph Wilson, Marina Machado, Luisa Moura, Dominik Krzemiński, Hakimeh Fadaei, Irem Ergun, Ifeoma Okoh, Aisha Alaagib, Oshan Mudannayake, Zaid Alyafeai, Vu Chien, Sebastian Ruder, Surya Guthikonda, Emad Alghamdi, Sebastian Gehrmann, Niklas Muennighoff, Max Bartolo, Julia Kreutzer, Ahmet Üstün, Marzieh Fadaee, and Sara HookerIn Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Aug 2024
@inproceedings{singh-etal-2024-aya, title = {Aya Dataset: An Open-Access Collection for Multilingual Instruction Tuning}, author = {Singh, Shivalika and Vargus, Freddie and D{'}souza, Daniel and Karlsson, B{\"o}rje and Mahendiran, Abinaya and Ko, Wei-Yin and Shandilya, Herumb and Patel, Jay and Mataciunas, Deividas and O{'}Mahony, Laura and Zhang, Mike and Hettiarachchi, Ramith and Wilson, Joseph and Machado, Marina and Moura, Luisa and Krzemi{\'n}ski, Dominik and Fadaei, Hakimeh and Ergun, Irem and Okoh, Ifeoma and Alaagib, Aisha and Mudannayake, Oshan and Alyafeai, Zaid and Chien, Vu and Ruder, Sebastian and Guthikonda, Surya and Alghamdi, Emad and Gehrmann, Sebastian and Muennighoff, Niklas and Bartolo, Max and Kreutzer, Julia and {\"U}st{\"u}n, Ahmet and Fadaee, Marzieh and Hooker, Sara}, editor = {Ku, Lun-Wei and Martins, Andre and Srikumar, Vivek}, booktitle = {Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)}, month = aug, year = {2024}, address = {Bangkok, Thailand}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.acl-long.620/}, doi = {10.18653/v1/2024.acl-long.620}, pages = {11521--11567}, } - NeuripsElo Uncovered: Robustness and Best Practices in Language Model EvaluationIn The Thirty-eighth Annual Conference on Neural Information Processing Systems, Aug 2024
@inproceedings{boubdir2024elo, title = {Elo Uncovered: Robustness and Best Practices in Language Model Evaluation}, author = {Boubdir, Meriem and Kim, Edward and Ermis, Beyza and Hooker, Sara and Fadaee, Marzieh}, booktitle = {The Thirty-eighth Annual Conference on Neural Information Processing Systems}, year = {2024}, url = {https://openreview.net/forum?id=Pc9LLjTL5f}, }
2023
- ArXivWhich Prompts Make The Difference? Data Prioritization For Efficient Human LLM EvaluationAug 2023
@misc{boubdir2023prompts, title = {Which Prompts Make The Difference? Data Prioritization For Efficient Human LLM Evaluation}, author = {Boubdir, Meriem and Kim, Edward and Ermis, Beyza and Fadaee, Marzieh and Hooker, Sara}, year = {2023}, eprint = {2310.14424}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2310.14424}, } - ArXivWhen Less is More: Investigating Data Pruning for Pretraining LLMs at ScaleAug 2023
Large volumes of text data have contributed significantly to the development of large language models (LLMs) in recent years. This data is typically acquired by scraping the internet, leading to pretraining datasets comprised of noisy web text. To date, efforts to prune these datasets down to a higher quality subset have relied on hand-crafted heuristics encoded as rule-based filters. In this work, we take a wider view and explore scalable estimates of data quality that can be used to systematically measure the quality of pretraining data. We perform a rigorous comparison at scale of the simple data quality estimator of perplexity, as well as more sophisticated and computationally intensive estimates of the Error L2-Norm and memorization. These metrics are used to rank and prune pretraining corpora, and we subsequently compare LLMs trained on these pruned datasets. Surprisingly, we find that the simple technique of perplexity outperforms our more computationally expensive scoring methods. We improve over our no-pruning baseline while training on as little as 30% of the original training dataset. Our work sets the foundation for unexplored strategies in automatically curating high quality corpora and suggests the majority of pretraining data can be removed while retaining performance.
@misc{marion2023more, title = {When Less is More: Investigating Data Pruning for Pretraining LLMs at Scale}, author = {Marion, Max and Üstün, Ahmet and Pozzobon, Luiza and Wang, Alex and Fadaee, Marzieh and Hooker, Sara}, year = {2023}, eprint = {2309.04564}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2309.04564}, } - ArXivInPars-v2: Large Language Models as Efficient Dataset Generators for Information RetrievalVitor Jeronymo, Luiz Bonifacio, Hugo Abonizio, Marzieh Fadaee, Roberto Lotufo, Jakub Zavrel, and Rodrigo NogueiraAug 2023
Recently, InPars introduced a method to efficiently use large language models (LLMs) in information retrieval tasks: via few-shot examples, an LLM is induced to generate relevant queries for documents. These synthetic query-document pairs can then be used to train a retriever. However, InPars and, more recently, Promptagator, rely on proprietary LLMs such as GPT-3 and FLAN to generate such datasets. In this work we introduce InPars-v2, a dataset generator that uses open-source LLMs and existing powerful rerankers to select synthetic query-document pairs for training. A simple BM25 retrieval pipeline followed by a monoT5 reranker finetuned on InPars-v2 data achieves new state-of-the-art results on the BEIR benchmark. To allow researchers to further improve our method, we open source the code, synthetic data, and finetuned models: https://github.com/zetaalphavector/inPars/tree/master/tpu
@misc{https://doi.org/10.48550/arxiv.2301.01820, title = {InPars-v2: Large Language Models as Efficient Dataset Generators for Information Retrieval}, author = {Jeronymo, Vitor and Bonifacio, Luiz and Abonizio, Hugo and Fadaee, Marzieh and Lotufo, Roberto and Zavrel, Jakub and Nogueira, Rodrigo}, year = {2023}, publisher = {arXiv}, doi = {10.48550/ARXIV.2301.01820}, url = {https://arxiv.org/abs/2301.01820}, copyright = {Creative Commons Attribution 4.0 International}, keywords = {Information Retrieval (cs.IR), Artificial Intelligence (cs.AI), FOS: Computer and information sciences, FOS: Computer and information sciences}, }
2022
- ArXivIn Defense of Cross-Encoders for Zero-Shot RetrievalGuilherme Rosa, Luiz Bonifacio, Vitor Jeronymo, Hugo Abonizio, Marzieh Fadaee, Roberto Lotufo, and Rodrigo NogueiraAug 2022
Bi-encoders and cross-encoders are widely used in many state-of-the-art retrieval pipelines. In this work we study the generalization ability of these two types of architectures on a wide range of parameter count on both in-domain and out-of-domain scenarios. We find that the number of parameters and early query-document interactions of cross-encoders play a significant role in the generalization ability of retrieval models. Our experiments show that increasing model size results in marginal gains on in-domain test sets, but much larger gains in new domains never seen during fine-tuning. Furthermore, we show that cross-encoders largely outperform bi-encoders of similar size in several tasks. In the BEIR benchmark, our largest cross-encoder surpasses a state-of-the-art bi-encoder by more than 4 average points. Finally, we show that using bi-encoders as first-stage retrievers provides no gains in comparison to a simpler retriever such as BM25 on out-of-domain tasks. The code is available at https://github.com/guilhermemr04/scaling-zero-shot-retrieval
@misc{https://doi.org/10.48550/arxiv.2212.06121, title = {In Defense of Cross-Encoders for Zero-Shot Retrieval}, author = {Rosa, Guilherme and Bonifacio, Luiz and Jeronymo, Vitor and Abonizio, Hugo and Fadaee, Marzieh and Lotufo, Roberto and Nogueira, Rodrigo}, year = {2022}, publisher = {arXiv}, doi = {10.48550/ARXIV.2212.06121}, url = {https://arxiv.org/abs/2212.06121}, copyright = {arXiv.org perpetual, non-exclusive license}, keywords = {Information Retrieval (cs.IR), Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences}, } - SIGIRInPars: Data Augmentation for Information Retrieval using Large Language ModelsLuiz Henrique Bonifacio, Hugo Abonizio, Marzieh Fadaee, and Rodrigo NogueiraIn SIGIR, Feb 2022
The information retrieval community has recently witnessed a revolution due to large pretrained transformer models. Another key ingredient for this revolution was the MS MARCO dataset, whose scale and diversity has enabled zero-shot transfer learning to various tasks. However, not all IR tasks and domains can benefit from one single dataset equally. Extensive research in various NLP tasks has shown that using domain-specific training data, as opposed to a general-purpose one, improves the performance of neural models. In this work, we harness the few-shot capabilities of large pretrained language models as synthetic data generators for IR tasks. We show that models finetuned solely on our unsupervised dataset outperform strong baselines such as BM25 as well as recently proposed self-supervised dense retrieval methods. Furthermore, retrievers finetuned on both supervised and our synthetic data achieve better zero-shot transfer than models finetuned only on supervised data. Code, models, and data are available at https://github.com/zetaalphavector/inpars
@inproceedings{bonifacio2022inpars, title = {InPars: Data Augmentation for Information Retrieval using Large Language Models}, author = {Henrique Bonifacio, Luiz and Abonizio, Hugo and Fadaee, Marzieh and Nogueira, Rodrigo}, year = {2022}, month = feb, booktitle = {SIGIR}, eprint = {2202.05144}, archiveprefix = {SIGIR}, primaryclass = {cs.CL}, url = {https://arxiv.org/pdf/2202.05144}, } - ArXivNo Parameter Left Behind: How Distillation and Model Size Affect Zero-Shot RetrievalGuilherme Moraes Rosa, Luiz Bonifacio, Vitor Jeronymo, Hugo Abonizio, Marzieh Fadaee, Roberto Lotufo, and Rodrigo NogueiraIn arXiv, Feb 2022
Recent work has shown that small distilled language models are strong competitors to models that are orders of magnitude larger and slower in a wide range of information retrieval tasks. This has made distilled and dense models, due to latency constraints, the go-to choice for deployment in real-world retrieval applications. In this work, we question this practice by showing that the number of parameters and early query-document interaction play a significant role in the generalization ability of retrieval models. Our experiments show that increasing model size results in marginal gains on in-domain test sets, but much larger gains in new domains never seen during fine-tuning. Furthermore, we show that rerankers largely outperform dense ones of similar size in several tasks. Our largest reranker reaches the state of the art in 12 of the 18 datasets of the Benchmark-IR (BEIR) and surpasses the previous state of the art by 3 average points. Finally, we confirm that in-domain effectiveness is not a good indicator of zero-shot effectiveness. Code is available at this https URL
@inproceedings{https://doi.org/10.48550/arxiv.2206.02873, title = {No Parameter Left Behind: How Distillation and Model Size Affect Zero-Shot Retrieval}, author = {Rosa, Guilherme Moraes and Bonifacio, Luiz and Jeronymo, Vitor and Abonizio, Hugo and Fadaee, Marzieh and Lotufo, Roberto and Nogueira, Rodrigo}, year = {2022}, booktitle = {arXiv}, doi = {10.48550/ARXIV.2206.02873}, url = {https://arxiv.org/abs/2206.02873}, copyright = {arXiv.org perpetual, non-exclusive license}, keywords = {Information Retrieval (cs.IR), Computation and Language (cs.CL), Performance (cs.PF), FOS: Computer and information sciences, FOS: Computer and information sciences}, }
2021
- ArXivmMARCO: A Multilingual Version of the MS MARCO Passage Ranking DatasetLuiz Bonifacio, Vitor Jeronymo, Hugo Queiroz Abonizio, Israel Campiotti, Marzieh Fadaee, Roberto Lotufo, and Rodrigo NogueiraIn arXiv, Feb 2021
The MS MARCO ranking dataset has been widely used for training deep learning models for IR tasks, achieving considerable effectiveness on diverse zero-shot scenarios. However, this type of resource is scarce in languages other than English. In this work, we present mMARCO, a multilingual version of the MS MARCO passage ranking dataset comprising 13 languages that was created using machine translation. We evaluated mMARCO by fine-tuning monolingual and multilingual re-ranking models, as well as a dense multilingual model on this dataset. Experimental results demonstrate that multilingual models fine-tuned on our translated dataset achieve superior effectiveness to models fine-tuned on the original English version alone. Our distilled multilingual re-ranker is competitive with non-distilled models while having 5.4 times fewer parameters. Lastly, we show a positive correlation between translation quality and retrieval effectiveness, providing evidence that improvements in translation methods might lead to improvements in multilingual information retrieval. The translated datasets and fine-tuned models are available at link.
@inproceedings{https://doi.org/10.48550/arxiv.2108.13897, title = {mMARCO: A Multilingual Version of the MS MARCO Passage Ranking Dataset}, author = {Bonifacio, Luiz and Jeronymo, Vitor and Abonizio, Hugo Queiroz and Campiotti, Israel and Fadaee, Marzieh and Lotufo, Roberto and Nogueira, Rodrigo}, year = {2021}, booktitle = {arXiv}, doi = {10.48550/ARXIV.2108.13897}, url = {https://arxiv.org/pdf/2108.13897}, copyright = {arXiv.org perpetual, non-exclusive license}, keywords = {Computation and Language (cs.CL), Artificial Intelligence (cs.AI), FOS: Computer and information sciences, FOS: Computer and information sciences}, archiveprefix = {arXiv}, bib = {https://dblp.org/rec/journals/corr/abs-2108-13897.bib}, }
2020
- ThesisUnderstanding and Enhancing the Use of Context for Machine TranslationMarzieh FadaeeOct 2020
Neural networks learn patterns from data to solve complex problems. To understand and infer meaning in language, neural models have to learn complicated nuances. Meaning is often determined from context. With context, languages allow meaning to be conveyed even when the specific words used are not known by the reader. To model this learning process, a system has to learn from a few instances in context and be able to generalize well to unseen cases. In this thesis, we focus on understanding certain potentials of contexts in neural models and design augmentation models to benefit from them. We focus on machine translation as an important instance of the more general language understanding problem. This task accentuates the value of capturing nuances of language and the necessity of generalization from few observations. The main problem we study in this thesis is what neural machine translation models learn from data and how we can devise more focused contexts to enhance this learning. Looking more in-depth into the role of context and the impact of data on learning models is essential to advance the Natural Language Processing (NLP) field. Understanding the importance of data in the learning process and how neural network models interact with and benefit from data can help develop more accurate NLP systems. Moreover, it helps highlight the vulnerabilities of current neural networks and provides insights into designing more robust models.
@book{mybook, title = {Understanding and Enhancing the Use of Context for Machine Translation}, author = {Fadaee, Marzieh}, year = {2020}, month = oct, publisher = {University of Amsterdam}, isbn = {9789464210590}, url = {https://dare.uva.nl/search?identifier=422122ad-f9d6-4952-9012-fcde9a820773}, } - SDPA New Neural Search and Insights Platform for Navigating and Organizing AI ResearchMarzieh Fadaee, Olga Gureenkova, Fernando Rejon Barrera, Carsten Schnober, Wouter Weerkamp, and Jakub ZavrelIn Proceedings of the First Workshop on Scholarly Document Processing, Nov 2020
To provide AI researchers with modern tools for dealing with the explosive growth of the research literature in their field, we introduce a new platform, AI Research Navigator, that combines classical keyword search with neural retrieval to discover and organize relevant literature. The system provides search at multiple levels of textual granularity, from sentences to aggregations across documents, both in natural language and through navigation in a domain specific Knowledge Graph. We give an overview of the overall architecture of the system and of the components for document analysis, question answering, search, analytics, expert search, and recommendations.
@inproceedings{fadaee-etal-2020-new, title = {A New Neural Search and Insights Platform for Navigating and Organizing {AI} Research}, author = {Fadaee, Marzieh and Gureenkova, Olga and Rejon Barrera, Fernando and Schnober, Carsten and Weerkamp, Wouter and Zavrel, Jakub}, year = {2020}, month = nov, booktitle = {Proceedings of the First Workshop on Scholarly Document Processing}, publisher = {Association for Computational Linguistics}, address = {Online}, pages = {207--213}, url = {https://www.aclweb.org/anthology/2020.sdp-1.23.pdf}, bib = {https://www.aclweb.org/anthology/2020.sdp-1.23.bib}, } - NGTThe Unreasonable Volatility of Neural Machine Translation ModelsMarzieh Fadaee and Christof MonzIn Proceedings of the Fourth Workshop on Neural Generation and Translation, Jul 2020
Recent works have shown that Neural Machine Translation (NMT) models achieve impressive performance, however, questions about understanding the behavior of these models remain unanswered. We investigate the unexpected volatility of NMT models where the input is semantically and syntactically correct. We discover that with trivial modifications of source sentences, we can identify cases where \textitunexpected changes happen in the translation and in the worst case lead to mistranslations. This volatile behavior of translating extremely similar sentences in surprisingly different ways highlights the underlying generalization problem of current NMT models. We find that both RNN and Transformer models display volatile behavior in 26% and 19% of sentence variations, respectively.
@inproceedings{fadaee-monz-2020-unreasonable, title = {The Unreasonable Volatility of Neural Machine Translation Models}, author = {Fadaee, Marzieh and Monz, Christof}, year = {2020}, month = jul, booktitle = {Proceedings of the Fourth Workshop on Neural Generation and Translation}, publisher = {Association for Computational Linguistics}, address = {Online}, pages = {88--96}, url = {https://www.aclweb.org/anthology/2020.ngt-1.10.pdf}, bib = {https://www.aclweb.org/anthology/2020.ngt-1.10.bib}, }
2018
- EMNLPBack-Translation Sampling by Targeting Difficult Words in Neural Machine TranslationMarzieh Fadaee and Christof MonzIn Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP), Brussels, Belgium, Jul 2018
Neural Machine Translation has achieved state-of-the-art performance for several language pairs using a combination of parallel and synthetic data. Synthetic data is often generated by back-translating sentences randomly sampled from monolingual data using a reverse translation model. While back-translation has been shown to be very effective in many cases, it is not entirely clear why. In this work, we explore different aspects of back-translation, and show that words with high prediction loss during training benefit most from the addition of synthetic data. We introduce several variations of sampling strategies targeting difficult-to-predict words using prediction losses and frequencies of words. In addition, we also target the contexts of difficult words and sample sentences that are similar in context. Experimental results for the WMT news translation task show that our method improves translation quality by up to 1.7 and 1.2 Bleu points over back-translation using random sampling for German-English and English-German, respectively
@inproceedings{D18-1040, title = {Back-Translation Sampling by Targeting Difficult Words in Neural Machine Translation}, author = {Fadaee, Marzieh and Monz, Christof}, year = {2018}, booktitle = {Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP)}, location = {Brussels, Belgium}, publisher = {Association for Computational Linguistics}, pages = {436--446}, url = {http://aclweb.org/anthology/D18-1040.pdf}, bib = {https://www.aclweb.org/anthology/D18-1040.bib}, } - LRECExamining the Tip of the Iceberg: A Data Set for Idiom TranslationMarzieh Fadaee, Arianna Bisazza, and Christof MonzIn Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), May 2018
Neural Machine Translation (NMT) has been widely used in recent years with significant improvements for many language pairs. Although state-of-the-art NMT systems are generating progressively better translations, idiom translation remains one of the open challenges in this field. Idioms, a category of multiword expressions, are an interesting language phenomenon where the overall meaning of the expression cannot be composed from the meanings of its parts. A first important challenge is the lack of dedicated data sets for learning and evaluating idiom translation. In this paper we address this problem by creating the first large-scale data set for idiom translation. Our data set is automatically extracted from a widely used German↔English translation corpus and includes, for each language direction, a targeted evaluation set where all sentences contain idioms and a regular training corpus where sentences including idioms are marked. We release this data set and use it to perform preliminary NMT experiments as the first step towards better idiom translation.
@inproceedings{2018arXiv180204681F, title = {Examining the Tip of the Iceberg: A Data Set for Idiom Translation}, author = {Fadaee, Marzieh and Bisazza, Arianna and Monz, Christof}, year = {2018}, month = may, booktitle = {Proceedings of the Eleventh International Conference on Language Resources and Evaluation ({LREC} 2018)}, publisher = {European Language Resources Association (ELRA)}, address = {Miyazaki, Japan}, url = {https://www.aclweb.org/anthology/L18-1148.pdf}, bib = {https://www.aclweb.org/anthology/L18-1148.bib}, }
2017
- ACLData Augmentation for Low-Resource Neural Machine TranslationMarzieh Fadaee, Arianna Bisazza, and Christof MonzIn Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL), Jul 2017
The quality of a Neural Machine Translation system depends substantially on the availability of sizable parallel corpora. For low-resource language pairs this is not the case, resulting in poor translation quality. Inspired by work in computer vision, we propose a novel data augmentation approach that targets low-frequency words by generating new sentence pairs containing rare words in new, synthetically created contexts. Experimental results on simulated low-resource settings show that our method improves translation quality by up to 2.9 BLEU points over the baseline and up to 3.2 BLEU over back-translation.
@inproceedings{fadaee-bisazza-monz:2017:Short2, title = {Data Augmentation for Low-Resource Neural Machine Translation}, author = {Fadaee, Marzieh and Bisazza, Arianna and Monz, Christof}, year = {2017}, month = jul, booktitle = {Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL)}, publisher = {Association for Computational Linguistics}, address = {Vancouver, Canada}, pages = {567--573}, url = {http://aclweb.org/anthology/P17-2090.pdf}, bib = {https://www.aclweb.org/anthology/P17-2090.bib}, } - ACLLearning Topic-Sensitive Word RepresentationsMarzieh Fadaee, Arianna Bisazza, and Christof MonzIn Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL), Jul 2017
Distributed word representations are widely used for modeling words in NLP tasks. Most of the existing models generate one representation per word and do not consider different meanings of a word. We present two approaches to learn multiple topic-sensitive representations per word by using Hierarchical Dirichlet Process. We observe that by modeling topics and integrating topic distributions for each document we obtain representations that are able to distinguish between different meanings of a given word. Our models yield statistically significant improvements for the lexical substitution task indicating that commonly used single word representations, even when combined with contextual information, are insufficient for this task.
@inproceedings{fadaee-bisazza-monz:2017:Short1, title = {Learning Topic-Sensitive Word Representations}, author = {Fadaee, Marzieh and Bisazza, Arianna and Monz, Christof}, year = {2017}, month = jul, booktitle = {Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL)}, publisher = {Association for Computational Linguistics}, address = {Vancouver, Canada}, pages = {441--447}, url = {http://aclweb.org/anthology/P17-2070.pdf}, bib = {https://www.aclweb.org/anthology/P17-2070.bib}, }
2013
- CICLINGAutomatic WordNet Construction Using Markov Chain Monte CarloPolibits, Jul 2013
WordNet is used extensively as a major lexical resource in information retrieval tasks. However, the qualities of existing Persian WordNets are far from perfect. They are either constructed manually which limits the coverage of Persian words, or automatically which results in unsatisfactory precision. This paper presents a fully-automated approach for constructing a Persian WordNet: A Bayesian Model with Markov chain Monte Carlo (MCMC) estimation. We model the problem of constructing a Persian WordNet by estimating the probability of assigning senses (synsets) to Persian words. By applying MCMC techniques in estimating these probabilities, we integrate prior knowledge in the estimation and use the expected value of generated samples to give the final estimates. This ensures great performance improvement comparing with Maximum-Likelihood and Expectation-Maximization methods. Our acquired WordNet has a precision of 90.46% which is a considerable improvement in comparison with automatically-built WordNets in Persian.
@article{fadaee2013automatic, title = {Automatic WordNet Construction Using Markov Chain Monte Carlo}, author = {Fadaee, Marzieh and Ghader, Hamidreza and Faili, Heshaam and Shakery, Azadeh}, year = {2013}, journal = {Polibits}, publisher = {Instituto Polit{\'e}cnico Nacional, Centro de Innovaci{\'o}n y Desarrollo Tecnol{\'o}gico en C{\'o}mputo}, volume = {47}, pages = {13--22}, url = {https://staff.fnwi.uva.nl/m.fadaee/files/pwn.pdf}, bib = {https://staff.fnwi.uva.nl/m.fadaee/files/pwn.bib}, }